- Home
- About Journals
-
Information for Authors/ReviewersEditorial Policies
Publication Fee
Publication Cycle - Process Flowchart
Online Manuscript Submission and Tracking System
Publishing Ethics and Rectitude
Authorship
Author Benefits
Reviewer Guidelines
Guest Editor Guidelines
Peer Review Workflow
Quick Track Option
Copyediting Services
Bentham Open Membership
Bentham Open Advisory Board
Archiving Policies
Fabricating and Stating False Information
Post Publication Discussions and Corrections
Editorial Management
Advertise With Us
Funding Agencies
Rate List
Kudos
General FAQs
Special Fee Waivers and Discounts
- Contact
- Help
- About Us
- Search




The Open Electrical & Electronic Engineering Journal
(Discontinued)
ISSN: 1874-1290 ― Volume 13, 2019
Hardware and Software Co-Design of Arabic Alphabets Recognition Platform for Blind and Visually Impaired Persons
Brahim Sabir1, *, Yassine Khazri1, Mohamed Moussetad1, Bouzekri Touri2
Abstract
Background:
Optical character Recognition (OCR) is a technic that converts scanned or printed text images into editable text. Many OCR solutions have been proposed and used for Latin and Chinese alphabets.
However not much can be found about OCRs for the handwriting scripts Arabic Alphabets, and especially to be used for blind and visually impaired persons.
This paper has been an attempt towards the development of an OCR for Arabic Alphabets dedicated to blind and visually impaired persons.
Method:
The proposed Optical Arabic Alphabets Recognition algorithm includes binarization of the inputted image, segmentation, feature extraction and a classification based on neural networks to match read Arabic alphabets with trained pattern.
The proposed algorithm has been developed using Matlab, and the solution was designed to be implemented on hardware platform and can be customized for mobile phones.
Conclusion:
The presented method has the benefit that the accuracy of recognition is comparable to other OCR algorithms.
Article Information

Identifiers and Pagination:
Year: 2017Volume: 11
First Page: 193
Last Page: 200
Publisher Id: TOEEJ-11-193
DOI: 10.2174/1874129001711010193
Article History:
Received Date: 31/05/2017Revision Received Date: 07/06/2017
Acceptance Date: 25/10/2017
Electronic publication date: 16/11/2017
Collection year: 2017
open-access license: This is an open access article distributed under the terms of the Creative Commons Attribution 4.0 International Public License (CC-BY 4.0), a copy of which is available at: https://creativecommons.org/licenses/by/4.0/legalcode. This license permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
* Address correspondence to this author LAPSTICE Lab, Language and Communication Department Faculty of Science Ben M’Sik, Casablanca, Morocco; Tel: 00212-650352972; E-mail: Sabir.brahim@hotmail.com
| Open Peer Review Details | |||
|---|---|---|---|
| Manuscript submitted on 31-05-2017 |
Original Manuscript | Hardware and Software Co-Design of Arabic Alphabets Recognition Platform for Blind and Visually Impaired Persons | |
1. INTRODUCTION
Arabic language is a cursive language, which has 28 alphabets Fig. (1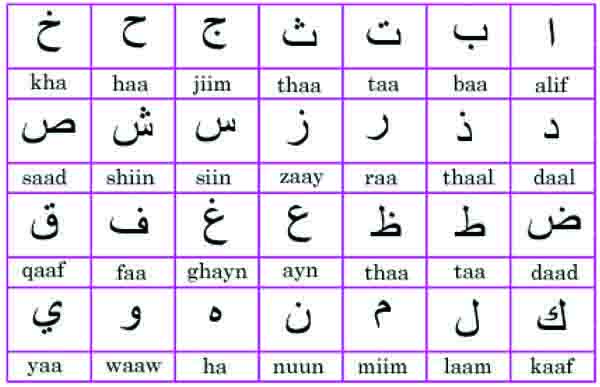 ), written from right to left, and each character has different form according to its position in the word [1C. Djeddi, and L. Souici-Meslati, "A texture based approach for arabic writer identification and verification", In: 2010 International Conference on Machine and Web Intelligence (ICMWI), IEEE: Algiers, Algeria, 2010, pp. 115-120.].
), written from right to left, and each character has different form according to its position in the word [1C. Djeddi, and L. Souici-Meslati, "A texture based approach for arabic writer identification and verification", In: 2010 International Conference on Machine and Web Intelligence (ICMWI), IEEE: Algiers, Algeria, 2010, pp. 115-120.].
For these reasons, Optical character recognition (OCR) of Arabic alphabets is more complicated than the recognition of the other languages (Latin, Chinese…)
The characteristics of Arabic do not allow direct implementation of many algorithms used for other Languages like English or Chinese. This is mainly because Arabic characters are always connected even when typewritten [1C. Djeddi, and L. Souici-Meslati, "A texture based approach for arabic writer identification and verification", In: 2010 International Conference on Machine and Web Intelligence (ICMWI), IEEE: Algiers, Algeria, 2010, pp. 115-120.].
The automatic recognition has large commercial importance. It has applications in cheque reading, collecting data from scanned documents, e-books producing. And dealing with the methods used for OCR, Artificial neural networks (ANNs) offer parallel processing of data in
ccontrast to the conventional sequential processing computing systems.
The ANN has been used in a wide variety of applications such as character recognition. Most of these applications are software-based [2A. Khader, J. Saudagar, and H.V. Mohammed, "Concatenation Technique for Extracted Arabic Characters for,Efficient Content-based Indexing and Searching", In: Proceedings of the Second International Conference on,Computer and Communication Technologies, Advances in Intelligent Systems and Computing: Hyderabad, India, 2015, pp. 24-26.].
Software implementations of the optical character recognition (OCR) systems have been reported extensively
In the research literature. Off-line printed and hand-written text recognition has been done using ANNs and other
Technologies such hidden Markov models (HMMs) [3M. Nidhal Abdi, and M. Khemakhem, "A model-based approach to offline text independent Arabic writer identification and Verification", Pattern Recognit., vol. 48, pp. 1890-1903, 2015.
[http://dx.doi.org/10.1016/j.patcog.2014.10.027] ].
A hardware-based ANN can take up different architectural forms such as perceptron, feed-forward multilayer Perceptron, radial basis function, etc [3M. Nidhal Abdi, and M. Khemakhem, "A model-based approach to offline text independent Arabic writer identification and Verification", Pattern Recognit., vol. 48, pp. 1890-1903, 2015.
[http://dx.doi.org/10.1016/j.patcog.2014.10.027] ].
The scope of this paper is optical character recognition of Arabic alphabets, dedicated to blind and visually impaired persons.
In this paper, after reviewing the state of the art in Section 2, the recognition process is explained in Section 3.
The hardware design of the solution is then described in Section 4; and section 5 is dedicated to the experimental results of the proposed solution.
Finally, conclusions are drawn in the last section, and directions for future works are presented.
 |
Fig. (1) Arabic Alphabets. |
2. RELATED WORKS
Many approaches are used to recognize Arabic alphabets such as Grapheme-based approach [4H. Malik, and M.A. Fahiem, "Segmentation of printed Urdu scripts using structural features", Proc. 2nd International Conference in Visualisation (VIZ’09), , 2009pp. 191-195
[http://dx.doi.org/10.1109/VIZ.2009.12] ], global features obtained with a spatial–temporal transform (wavelets) [5S. Gazzah, and N. Ben Amara, "Arabic handwriting texture analysis for writer identification using the DWT-lifting scheme", In: The Ninth International Conference on Document Analysis and Recognition (ICDAR 2007), vol. 2. IEEE: Curitiba, Parana, Brazil, 2007, pp. 1133-1137.], directional/angular distributions [6M. Bulacu, L. Schomaker, and A. Brink, "Text-independent writer identification and verification on offline arabic handwriting", in: Document Analysis and Recognition, 2007pp. 769-773 ICDAR 2007. Ninth International Conference on, vol. 2, IEEE,, Curitiba, Parana, Brazil
[http://dx.doi.org/10.1109/ICDAR.2007.4377019] , 7M.N. Abdi, M. Khemakhem, and H. Ben-Abdallah, "A novel approach for off-line arabic writer identification based on stroke feature combination ", In: The 24th International Symposium on Computer and Information Sciences (ISCIS 2009), IEEE: Guzelyurt, Northern Cyprus, 2009, pp. 597-600.], word/phrase measurements [6M. Bulacu, L. Schomaker, and A. Brink, "Text-independent writer identification and verification on offline arabic handwriting", in: Document Analysis and Recognition, 2007pp. 769-773 ICDAR 2007. Ninth International Conference on, vol. 2, IEEE,, Curitiba, Parana, Brazil
[http://dx.doi.org/10.1109/ICDAR.2007.4377019] , 8S. Ghoniemy, S. Fadel, and M. Asif, "A multipurpose Multi-Agent System based on a loosely coupled architecture to speedup the DTW algorithm for Arabic", In: International Journal of informatics and medical data processing (JIMDP), vol. 1, 2. 2016, pp. 14-21.], statistical features, such as texture measurements [6M. Bulacu, L. Schomaker, and A. Brink, "Text-independent writer identification and verification on offline arabic handwriting", in: Document Analysis and Recognition, 2007pp. 769-773 ICDAR 2007. Ninth International Conference on, vol. 2, IEEE,, Curitiba, Parana, Brazil
[http://dx.doi.org/10.1109/ICDAR.2007.4377019] , 7M.N. Abdi, M. Khemakhem, and H. Ben-Abdallah, "A novel approach for off-line arabic writer identification based on stroke feature combination ", In: The 24th International Symposium on Computer and Information Sciences (ISCIS 2009), IEEE: Guzelyurt, Northern Cyprus, 2009, pp. 597-600.], grapheme distributions [6M. Bulacu, L. Schomaker, and A. Brink, "Text-independent writer identification and verification on offline arabic handwriting", in: Document Analysis and Recognition, 2007pp. 769-773 ICDAR 2007. Ninth International Conference on, vol. 2, IEEE,, Curitiba, Parana, Brazil
[http://dx.doi.org/10.1109/ICDAR.2007.4377019] ], gray-level statistics [9N. Das, A.F. Mollah, and S. Saha, "Handwritten Arabic Numeral Recognition using a Multi Layer Perceptron", In: Proceeding National Conference on Recent Trends in Information Systems, 2006, pp. 200-203., 10M. Khemakhem, and A. Belghiti, "Towards A Distributed Arabic OCR Based on the DTW Algorithm: Performance Analysis", Int. Arab J. Inf. Technol., 2009.], cross-correlation distributions [11A.U. Hasan, S.B. Ahmed, F. Rashid, F. Shafait, and T.M. Breuel, "Offline printed Urdu Nastaleeq script recognition with Bidirectional LSTM networks", 12th International Conference on Document Analysis and Recognition (ICDAR’13), 2012 pp. 1061-1065., 12S. Al-Ma’adeed, E. Mohammed, and D. Al Kassis, "Writer identification using edgebased directional probability distribution features for arabic words", In: in: IEEE/ACS International Conference on Computer Systems and Applications (AICCSA 2008), IEEE: Doha, Qatar, 2008, pp. 582-590.], Dynamic time Wrap [13Z.A. Shah, "Ligature based optical character recognition of Urdu-Nastaleeq Font", Proc. 6th International Multitopic IEEE Conference (INMIC’02), , 2002pp. 25-25
[http://dx.doi.org/10.1109/INMIC.2002.1310132] ], Artificial neural networks(ANN) [14M.N. Abdi, M. Khemakhem, and H. Ben-Abdallah, "Off-line text-independent arabic writer identification using contour-based features", Int. J. Signal Image Process., vol. 1, pp. 4-11, 2010.] [15A. Zidouri, "Oran: A basis for an arabic OCR system", Arab. J. Sci. Eng., vol. 31, no. 1B, 2005.], or Kernel methods [16T. Sari, L.S. Mokhtar, and M. Sellami, "Off-line handwritten Arabic character, segmentation algorithm: ACSA", Proceedings of the Eighth International Workshop on Frontiers in Handwriting Recognition (IWFHR’02), 2002
[http://dx.doi.org/10.1109/IWFHR.2002.1030952] ] such as Support Vector Machines (SVM).
And dealing with the rates of recognition, a rate of 97% was obtained by Dynamic Time Warp (DTW) algorithm [13Z.A. Shah, "Ligature based optical character recognition of Urdu-Nastaleeq Font", Proc. 6th International Multitopic IEEE Conference (INMIC’02), , 2002pp. 25-25
[http://dx.doi.org/10.1109/INMIC.2002.1310132] ]; a Multi-Layer Perceptron (MLP) based classifier yields an average recognition rate of 94.93% [17G. a. Abandah, F. T. Jamour, and E. a. Qaralleh, "Recognizing handwritten Arabic words using grapheme segmentation and recurrent neural networks", International Journal on Document Analysis and Recognition (IJDAR) Mar., 2014.
[http://dx.doi.org/10.1007/s10032-014-0218-7] ], Grapheme-based has been a rate of 96% [4H. Malik, and M.A. Fahiem, "Segmentation of printed Urdu scripts using structural features", Proc. 2nd International Conference in Visualisation (VIZ’09), , 2009pp. 191-195
[http://dx.doi.org/10.1109/VIZ.2009.12] ]; recurrent neural network word recognition rate is 94.76% by Abandah et al. [17G. a. Abandah, F. T. Jamour, and E. a. Qaralleh, "Recognizing handwritten Arabic words using grapheme segmentation and recurrent neural networks", International Journal on Document Analysis and Recognition (IJDAR) Mar., 2014.
[http://dx.doi.org/10.1007/s10032-014-0218-7] ]
Hidden Markov Models (HMM) with a rate above 90% [18I.H. Witten, and E. Frank, Data Mining., 2nd ed Morgan Kaufman Publishers: San Francisco, CA, 2005.].
Statistical model yields a rate of 99.4% [19N. Abdi, and M. Khemakhem, "Arabic writer identification and verification using template matching analysis of texture ", In: 2012 IEEE 12th International Conference on Computer and Information Technology (CIT), IEEE: Chengdu, China, 2012, pp. 592-597.] [20C. Djeddi, and L. Souici-Meslati, "Artificial immune recognition system for arabic writer identification", 2011 Fourth International Symposium on Innovation in Information & Communication Technology (ISIICT), 2011 pp. 159-165
[http://dx.doi.org/10.1109/ISIICT.2011.6149612] ] [21A. Graves, M. Liwicki, S. Fernández, R. Bertolami, H. Bunke, and J. Schmidhuber, "A novel connectionist system for unconstrained handwriting recognition", IEEE Trans. Pattern Anal. Mach. Intell., vol. 31, no. 5, pp. 855-868, 2009.
[http://dx.doi.org/10.1109/TPAMI.2008.137] [PMID: 19299860] ]. Recognition accuracies was 79% by Pal and Sarkar [22U. Pal, and A. Sarkar, "Recognition of printed Urdu script", Proceedings of the Seventh International Conference on Document Analysis and Recognition (ICDAR’03), 2003
[http://dx.doi.org/10.1109/ICDAR.2003.1227844] ], and 97.8% by Shamsher et al. [23I. Shamsher, Z. Ahmad, J.K. Orakzai, and A. Adnan, "OCR for printed Urdu script using feed forward neural network", Proceedings of World Academy of Science, Engineering and Technology, vol. 23, pp. 172-175, 2007.].
Khan et al. achieved a rate of 96.2% [24K. Khan, R. Ullah, N.A. Khan, and K. Naveed, "Urdu character recognition using principal component analysis", Int. J. Comput. Appl., p. 60, 2012.], however Sabbour and Safiat yield a recognition rate of 91% [25N. Sabbour, and F. Shafait, "A segmentation-free approach to Arabic and Urdu OCR", In: Proceeding of SPIE International Society for Optics and Photonics, vol. 86580. International Society for Optics and Photonics., 2012.].
The ANN achieved 93% correct character recognition [14M.N. Abdi, M. Khemakhem, and H. Ben-Abdallah, "Off-line text-independent arabic writer identification using contour-based features", Int. J. Signal Image Process., vol. 1, pp. 4-11, 2010.].
3. MATERIAL AND SOFTWARE USED
MATLAB 7.10.0 R2010a Version /64-bit software is used to implement the proposed Arabic OCR algorithm on an Dell Intel Core CPU M640@2.8GHZ, RAM 4Go, machine running a 64-bit operating, system -MS Windows 7.
The Cyclone II FPGA board is used to implement the VHDL code generated for matlab files.
The software ModelSim-Intel FPGA-2016 was used to simulate hardware design of our OCR.
4. PROPOSED METHOD
Fig. (2 ) shows The main steps To build an Optical character recognition (OCR) which will offer blind and visually impaired persons the capacity to scan printed text and then speak it back in synthetic speech.
) shows The main steps To build an Optical character recognition (OCR) which will offer blind and visually impaired persons the capacity to scan printed text and then speak it back in synthetic speech.
 |
Fig. (2) Main steps of proposed method. |
In optical character recognition step, we followed: training procedure, image acquisition, preprocessing, segmentation, feature extraction and classification [26A. Al-Shatnawi, F. Al-Zawaideh, S. Al-Salaimeh, and K. Omar, "“Offline Arabic Test Recognition – An Overview,” Irbid National,University, Jordan", Conf., vol. 1, no. 5, pp. 184-192, 2011. [WCSIT].].
The speech synthesizer tool step is not on the scope of the present paper.
The following sections explain these steps and the used techniques in the experiments of this paper.
4.1. Preprocessing
Preprocessing steps include: Binarization, filtering and smoothing.
The input image will be preprocessed in order to perform noise cleaning.
Convert to gray scale, binary image, remove salt and paper noise.
A Color, a graylevel, or a binary image of Arabic alphabet will be binarized based on:
For each point (x,y), X is random variable [0,254]:
If I (x,y) < X: level of the selected point = 1.
If I (x,y) > X: level of the selected point = 0.
4.2. Training Procedure
In order to build our artificial neural network, we used The Backpropagation Algorithm which has as input the segmented alphabets (matrix 35 * 35) and as outputs (vector column of 28 alphabets).
The training begins with random weights, and the goal is to adjust them so that the error will be minimal.
We note, A: Activation function, x input and w the weight:
Sigmoidal output (O) function:
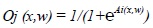 |
(1) |
The goal of the training process is to obtain a desired output when certain Inputs (Matrix of Arabic Alphabet) are given.
Since the error is the difference between the actual and the desired output, the error depends on the weights, and we need to adjust the weights in order to minimize the error E (difference between Output function and the distance):
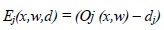 |
(2) |
The error of the network will be the sum of the errors of all the neurons in the output layer:
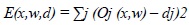 |
(3) |
The error will generate confusion rates mentioned in tables of experimental results section.
The input to the training process is a set of Arabic alphabets’ images which ultimately produce the weight matrix of the recognizer’s neural network.
4.3. Image Acquisition
The alphabets are scanned or captured during the step of image acquisition. The saved image file format is GIF, bmp or jpeg.
4.4. Segmentation
The segmentation algorithm will extract each part as separate characters. Fig. 3 shows segmentation of the alphabet "Sin".
shows segmentation of the alphabet "Sin".
The non-cursive characteristic of the Arabic Alphabets facilitates the preprocessing step.
The segmentation step will be achieved in order to construct the input matrix (35 * 35).
 |
Fig. 3 Segmentation step of the alphabets sin (س). |
4.5. Classification
The classification assigns an unknown feature into a predefined class (character shape). A number of classification methods are used for Arabic text recognition for examples: Template Matching, Statistical Techniques, Syntactic Techniques, Neural Networks and Hidden Markov Model [27A. Beg, "An Efficient Realization of an OCR System Using HDL", In: International Conference on Artificial Intelligence (ICAI'08), Las Vegas, NV: United States, 2008.].
In this paper, the neural network classifier will be used to classify the inputted Arabic alphabets.
5. HARDWARE DESIGN
We opted for hardware implementation, in order to improve the speed of ANN, compared with software implementation.
An ANN’s structural details include number of inputs and outputs, and the number of layers, and activation functions (AFs).
We Implement the individual VHDL modules: adder, multiplier, shifter (divider), and AF (ramp, and piece-wise linear approximation of a sigmoid); for a single neuron.

5.1. Activation Function Implementation
All the neurons in the entire ANN employ the same AF (activation function), but the output layer may use a different AF type.
There are several ways of approximating the sigmoid function [28B. Sabir, A. Jadir, Y. Khazri, B. Touri, and M. Moussetad, "Multiple Classifiers Combination Applied to OCR of Tifinagh Alphabets", Int. J. Eng. Innovat. Technol., vol. 4, no. 5, pp. 1-8, 2014. [IJEIT].], We opted for the combinational approximation.
The AF output ranges from -94 to 94.
In order to reduce the cost we replace the division operation with simple right shifts: 2-bit shifting for division-by-4, and 6-bit shifting for division by- 64.
5.2. Threshold Function Implementation
The threshold function in our neurons outputs ‘0’ if the input is less than or equal to zero; else the output is ‘1’.
The hardware implementation of this function simply comprises of a most-significant bit comparator.
5.3. Model Simulation and Analysis
The proposed VHDL models were simulated using ModelSim-Intel FPGA-2016.
We opted for the input samples which are made up of 35x35 grids which is the matrix generated from Arabic alphabets’ segmentation.
6. EXPERIMENTAL RESULTS
The Table 2 summarizes the recognition rates of proposed algorithm on software hardware platform.
Tests were done using images of size 2500*2500 pixels.
The recognition rate of software based solution is higher than the recognition rates of the one implemented in hardware platform; however the time consumption of hardware platform is reduced by 86%.
The higher error rate in hardware platform could be mainly attributed to the following factors:
- The Approximation of the sigmoid AF.
- The use of large grid, however it will lead to higher hardware implementation cost.

CONCLUSION
In this paper, we present an OCR for Arabic alphabets. The OCR system has been quite successful in the recognition of input images. The experimental result shows us that with the test image (matrix of 35*35) with same font type the accuracy rate is 96.4% on software implementation.
Searches and comparisons are time consuming, however the accuracy of proposed method is high compared to other OCRs
A comparison study of proposed algorithm on hardware platform is carried out with proposed algorithm (software only).
Future work for the alphabets with high rates of confusion a multiple classifier will be implemented, Additional training samples could improve the ANN learning ability, hence improving the prediction accuracy. This may not affect the ANN hardware configuration.
In this paper the hardware implementation of the ANN had lower accuracy than its software counterpart.
The hardware’s character recognition accuracy is still significantly high at 85.7%.
One reason for reduced accuracy is the approximation of non-linear sigmoid Activation Function.
Further improvements are possible without significantly altering the hardware, for example, by using a larger dataset for training, and possible implementation of proposed design using synthesis tools (such as Synopsys Design Compiler) in order to save on adder hardware (inside a neuron) .
The proposed solution can be customized to be implemented in mobile phones.
CONSENT FOR PUBLICATION
Not applicable.
CONFLICT OF INTEREST
The author (editor) declares no conflict of interest, financial or otherwise.
ACKNOWLEDGEMENTS
I would like to thank Mrs. Maida Bermudez her valuable contribution.
REFERENCES
| [1] | C. Djeddi, and L. Souici-Meslati, "A texture based approach for arabic writer identification and verification", In: 2010 International Conference on Machine and Web Intelligence (ICMWI), IEEE: Algiers, Algeria, 2010, pp. 115-120. |
| [2] | A. Khader, J. Saudagar, and H.V. Mohammed, "Concatenation Technique for Extracted Arabic Characters for,Efficient Content-based Indexing and Searching", In: Proceedings of the Second International Conference on,Computer and Communication Technologies, Advances in Intelligent Systems and Computing: Hyderabad, India, 2015, pp. 24-26. |
| [3] | M. Nidhal Abdi, and M. Khemakhem, "A model-based approach to offline text independent Arabic writer identification and Verification", Pattern Recognit., vol. 48, pp. 1890-1903, 2015. [http://dx.doi.org/10.1016/j.patcog.2014.10.027] |
| [4] | H. Malik, and M.A. Fahiem, "Segmentation of printed Urdu scripts using structural features", Proc. 2nd International Conference in Visualisation (VIZ’09), , 2009pp. 191-195 [http://dx.doi.org/10.1109/VIZ.2009.12] |
| [5] | S. Gazzah, and N. Ben Amara, "Arabic handwriting texture analysis for writer identification using the DWT-lifting scheme", In: The Ninth International Conference on Document Analysis and Recognition (ICDAR 2007), vol. 2. IEEE: Curitiba, Parana, Brazil, 2007, pp. 1133-1137. |
| [6] | M. Bulacu, L. Schomaker, and A. Brink, "Text-independent writer identification and verification on offline arabic handwriting", in: Document Analysis and Recognition, 2007pp. 769-773 ICDAR 2007. Ninth International Conference on, vol. 2, IEEE,, Curitiba, Parana, Brazil [http://dx.doi.org/10.1109/ICDAR.2007.4377019] |
| [7] | M.N. Abdi, M. Khemakhem, and H. Ben-Abdallah, "A novel approach for off-line arabic writer identification based on stroke feature combination ", In: The 24th International Symposium on Computer and Information Sciences (ISCIS 2009), IEEE: Guzelyurt, Northern Cyprus, 2009, pp. 597-600. |
| [8] | S. Ghoniemy, S. Fadel, and M. Asif, "A multipurpose Multi-Agent System based on a loosely coupled architecture to speedup the DTW algorithm for Arabic", In: International Journal of informatics and medical data processing (JIMDP), vol. 1, 2. 2016, pp. 14-21. |
| [9] | N. Das, A.F. Mollah, and S. Saha, "Handwritten Arabic Numeral Recognition using a Multi Layer Perceptron", In: Proceeding National Conference on Recent Trends in Information Systems, 2006, pp. 200-203. |
| [10] | M. Khemakhem, and A. Belghiti, "Towards A Distributed Arabic OCR Based on the DTW Algorithm: Performance Analysis", Int. Arab J. Inf. Technol., 2009. |
| [11] | A.U. Hasan, S.B. Ahmed, F. Rashid, F. Shafait, and T.M. Breuel, "Offline printed Urdu Nastaleeq script recognition with Bidirectional LSTM networks", 12th International Conference on Document Analysis and Recognition (ICDAR’13), 2012 pp. 1061-1065. |
| [12] | S. Al-Ma’adeed, E. Mohammed, and D. Al Kassis, "Writer identification using edgebased directional probability distribution features for arabic words", In: in: IEEE/ACS International Conference on Computer Systems and Applications (AICCSA 2008), IEEE: Doha, Qatar, 2008, pp. 582-590. |
| [13] | Z.A. Shah, "Ligature based optical character recognition of Urdu-Nastaleeq Font", Proc. 6th International Multitopic IEEE Conference (INMIC’02), , 2002pp. 25-25 [http://dx.doi.org/10.1109/INMIC.2002.1310132] |
| [14] | M.N. Abdi, M. Khemakhem, and H. Ben-Abdallah, "Off-line text-independent arabic writer identification using contour-based features", Int. J. Signal Image Process., vol. 1, pp. 4-11, 2010. |
| [15] | A. Zidouri, "Oran: A basis for an arabic OCR system", Arab. J. Sci. Eng., vol. 31, no. 1B, 2005. |
| [16] | T. Sari, L.S. Mokhtar, and M. Sellami, "Off-line handwritten Arabic character, segmentation algorithm: ACSA", Proceedings of the Eighth International Workshop on Frontiers in Handwriting Recognition (IWFHR’02), 2002 [http://dx.doi.org/10.1109/IWFHR.2002.1030952] |
| [17] | G. a. Abandah, F. T. Jamour, and E. a. Qaralleh, "Recognizing handwritten Arabic words using grapheme segmentation and recurrent neural networks", International Journal on Document Analysis and Recognition (IJDAR) Mar., 2014. [http://dx.doi.org/10.1007/s10032-014-0218-7] |
| [18] | I.H. Witten, and E. Frank, Data Mining., 2nd ed Morgan Kaufman Publishers: San Francisco, CA, 2005. |
| [19] | N. Abdi, and M. Khemakhem, "Arabic writer identification and verification using template matching analysis of texture ", In: 2012 IEEE 12th International Conference on Computer and Information Technology (CIT), IEEE: Chengdu, China, 2012, pp. 592-597. |
| [20] | C. Djeddi, and L. Souici-Meslati, "Artificial immune recognition system for arabic writer identification", 2011 Fourth International Symposium on Innovation in Information & Communication Technology (ISIICT), 2011 pp. 159-165 [http://dx.doi.org/10.1109/ISIICT.2011.6149612] |
| [21] | A. Graves, M. Liwicki, S. Fernández, R. Bertolami, H. Bunke, and J. Schmidhuber, "A novel connectionist system for unconstrained handwriting recognition", IEEE Trans. Pattern Anal. Mach. Intell., vol. 31, no. 5, pp. 855-868, 2009. [http://dx.doi.org/10.1109/TPAMI.2008.137] [PMID: 19299860] |
| [22] | U. Pal, and A. Sarkar, "Recognition of printed Urdu script", Proceedings of the Seventh International Conference on Document Analysis and Recognition (ICDAR’03), 2003 [http://dx.doi.org/10.1109/ICDAR.2003.1227844] |
| [23] | I. Shamsher, Z. Ahmad, J.K. Orakzai, and A. Adnan, "OCR for printed Urdu script using feed forward neural network", Proceedings of World Academy of Science, Engineering and Technology, vol. 23, pp. 172-175, 2007. |
| [24] | K. Khan, R. Ullah, N.A. Khan, and K. Naveed, "Urdu character recognition using principal component analysis", Int. J. Comput. Appl., p. 60, 2012. |
| [25] | N. Sabbour, and F. Shafait, "A segmentation-free approach to Arabic and Urdu OCR", In: Proceeding of SPIE International Society for Optics and Photonics, vol. 86580. International Society for Optics and Photonics., 2012. |
| [26] | A. Al-Shatnawi, F. Al-Zawaideh, S. Al-Salaimeh, and K. Omar, "“Offline Arabic Test Recognition – An Overview,” Irbid National,University, Jordan", Conf., vol. 1, no. 5, pp. 184-192, 2011. [WCSIT]. |
| [27] | A. Beg, "An Efficient Realization of an OCR System Using HDL", In: International Conference on Artificial Intelligence (ICAI'08), Las Vegas, NV: United States, 2008. |
| [28] | B. Sabir, A. Jadir, Y. Khazri, B. Touri, and M. Moussetad, "Multiple Classifiers Combination Applied to OCR of Tifinagh Alphabets", Int. J. Eng. Innovat. Technol., vol. 4, no. 5, pp. 1-8, 2014. [IJEIT]. |