- Home
- About Journals
-
Information for Authors/ReviewersEditorial Policies
Publication Fee
Publication Cycle - Process Flowchart
Online Manuscript Submission and Tracking System
Publishing Ethics and Rectitude
Authorship
Author Benefits
Reviewer Guidelines
Guest Editor Guidelines
Peer Review Workflow
Quick Track Option
Copyediting Services
Bentham Open Membership
Bentham Open Advisory Board
Archiving Policies
Fabricating and Stating False Information
Post Publication Discussions and Corrections
Editorial Management
Advertise With Us
Funding Agencies
Rate List
Kudos
General FAQs
Special Fee Waivers and Discounts
- Contact
- Help
- About Us
- Search




The Open Medical Informatics Journal
(Discontinued)
ISSN: 1874-4311 ― Volume 13, 2019
Meta-Analysis of Multi-Arm Trials Using Empirical Logistic Transform
Hathaikan Chootrakool, Jian Qing Shi*
Abstract
Meta-analysis of multi-arm trials has been used increasingly in recent years. The aim of meta-analysis for multi-arm trials is to combine evidence from all possible similar studies. In this paper we propose normal approximation models by using empirical logistic transform to compare different treatments in multi-arm trials, allowing studies of both direct and indirect comparisons. Additionally, a hierarchical structure is introduced in the models to address the problem of heterogeneity among different studies. The proposed models are performed using the data from 31 randomized clinical trials (RCTs) which determine the efficacy of antiplatelet therapy in maintaining vascular patency.
Article Information
Identifiers and Pagination:
Year: 2008Volume: 2
First Page: 112
Last Page: 116
Publisher Id: TOMINFOJ-2-112
DOI: 10.2174/1874431100802010112
Article History:
Received Date: 27/3/2008Revision Received Date: 05/5/2008
Acceptance Date: 19/5/2009
Electronic publication date: 6/6/2008
Collection year: 2008
open-access license: This is an open access article licensed under the terms of the Creative Commons Attribution Non-Commercial License (http://creativecommons.org/licenses/by-nc/3.0/) which permits unrestricted, non-commercial use, distribution and reproduction in any medium, provided the work is properly cited.
* Address correspondence to this author at the School of Mathematics and Statistics, University of Newcastle, Newcastle uypon Tyne, NE1 7RU, UK; E-mail: j.q.shi@ncl.ac.uk
| Open Peer Review Details | |||
|---|---|---|---|
| Manuscript submitted on 27-3-2008 |
Original Manuscript | Meta-Analysis of Multi-Arm Trials Using Empirical Logistic Transform | |
1. INTRODUCTION
Most meta-analysis has focused on summarising of treatment effect measures based on comparisons of two treatments. Some meta-analysis data sets contain information on more than two treatments comparing evidence of multi-arm trials comparisons. This type of data is called Multi-arm trials in this paper although some authors call it mixed treatment comparison (MTC). Higgins and Whitehead [1Higgins JPT, Whitehead A. Borrowing strength from external trials in a meta-analysis Stat Med 1996; 15: 2733-49.] presented a random effect meta-analysis for binary data and introduced an idea of ‘borrowing strength’ from indirect comparison. They considered using the general parameter approach and the exact binomial approach to estimate parameters of interest in a meta-analysis. Lu and Ades [2Lu G, Ades AE. Combination of direct and indirect evidence in mixed treatment comparison Stat Med 2004; 23: 3105-24.] proposed a Bayesian hierarchical model using the Markov Chain Monte Carlo to represent meta-analysis of multi-arm trials. Inconsistency in multi-arm trials evidence structure was examined by Lu and Ades [3Lu G, Ades AE. Assessing evidence inconsistency in mixed treatment comparisons J Am Stat Assoc 2006; 101(474): 447-59.]. They performed a Bayesian hierarchical model with fixed effects or random effects for fitting multi-arm trials under the assumption that the available evidence sources were consistent in estimating all treatment contrasts.
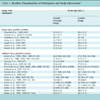
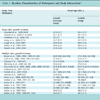
In meta-analysis for comparing two treatments, we usually collected all the studies providing information on comparing those two treatments directly. However some studies in multi-arm trials give a useful information on indirect comparison in a situation where the treatments have not been directly compared. Thus, there are two types of treatment comparisons in meta-analysis of multi-arm trials: one is to compare two treatments directly, the other is to use information from indirect comparisons. For example, from antiplatelet data given in Table 2, there are three groups of studies available: treatments A, B and C; the control group of the meta-analysis is treatment C, studies in group GAB compare treatment A versus B, studies in group GBC compare treatment B versus C, and studies in group GCA compare treatment C versus A and our aim is to compare treatment A versus B. The studies in group GBC and GCA then provide the indirect comparison for treatment A versus B. Later in this paper, we will blur the concept between direct and indirect comparisons since our model can actually give estimate of the treatment effect between any two arms of all treatments involved in the multi-arm trials.
The direct and indirect comparisons for RCTs in a meta-analysis have been expressed by several authors [2Lu G, Ades AE. Combination of direct and indirect evidence in mixed treatment comparison Stat Med 2004; 23: 3105-24.-6Song F, Altman DG, Glenny A, Deeks JJ. Validity of indirect comparison for estimating effcacy of competing intewrventions: empirical evidence from published meta-analyses BMJ 2003; 326: 427-6.]. In this paper we propose a normal approximation model based on the empirical logistic transform. There are at least two advantages comparing to other methods: (1) the proposed empirical log-odds ratio models exclude the trial effects and then it will give an unbiased estimate for treatment effect while the other methods may give a biased estimates in some circumstances (see for example the discussion on page 59 in [7Cox DR, Snell EJ. Analysis of Binary data. 2nd. London: Chapman and Hall 1989.]); (2) The computation is very efficient and fast. The method has been used for the systematic reviews of antiplatelet trialists’ collaboration [8ATC Collaboration. Collaborative overview of randomised trials of antiplatelet therapy-II: maintenance of vascular graft or arterial patency by antiplatelet therapy BMJ 1994; 308: 159-68.] which investigates the efficacy of antiplatelet therapy in maintaining vascular patency in various categories of patients. The paper is organized as follows. We begin by introducing the data structure of multi-arm trials and performing empirical log-odds and empirical log-odds ratio models in Section 2.1. The maximum likelihood method is illustrated in Section 2.2. The last section concludes the ideas of this paper and gives some comments.
2. METHODOLOGY
In this section we shall propose our ideas of empirical log-odds and empirical log-odds ratio models through the antiplatelet data. Clinically, after coronary artery revascularisation of patients, whether by coronary artery bypass grafting or by percutaneous transluminal coronary angioplasty, angiographic studies show substantial rates of re-occlusion [9Gillum RF. Coronary artery bypass surgery and coronary angiography in the United states, 1979-1985 Control Clin Trials 1987; 113: 1255-60.]. Experimental and clinical evidence suggests that antiplatelet therapy may help prevent vascular graft or arterial occlusions, particularly during the period soon after vascular procedures, before any intimal damage has healed [10Bonchek Li, Boerboom Le, Olinger GN. Prevention of lipid accumulation in experimental vein bypass grafts by antiplatelet therapy Circulation 1982; 66: 338-41., 11Pirk J, Ruzbarsky V, Konig J. The effect of antiaggregating drugs on the patency of grafts in the arterial system World J Surg 1990; 4: 615-20.]. The data was analyzed in order to determine the efficacy of antiplatelet therapy in maintaining vascular patency. There are 31 RCTs in total investigating the use of aspirin plus dipyridamole, or aspirin alone, in the comparison with the control group. The trials compare three treatments A (aspirin plus dipyridamole), B (aspirin only) and C (control group), where 6 trials (1-6) compare A, B and C, 4 trials (7-10) compare A and B, 13 trials (11-24) compare A and C and 7 trials (25-31) compare B and C. The data is shown in Table 2.
2.1. Models
For convenience, we partition the data set into four groups. Let G1 = {1, ...,6}, G2 = {7, ...,10 }, G3 = {11, ...,24} and G4 = {25,...,31} be four sets of studies comparing treatment A versus B versus C, A versus B, A versus C and B versus C, respectively. Let riA, riB and riC be the numbers of patients that have reocclusions on treatments A, B and C respectively where the ith study is in
The above models are called empirical log-odds models. The
It is called log-odds ratio between treatment A and treatment C, measuring the effect of treatment A comparing to the control group C. This is the parameter of interest. The main purpose of the meta-analysis is to find the overall estimates of the log-odds ratios between treatments A versus C, B versus C and A versus B. We may assume a fixed effect or a random effect. The fixed effect model assumes that all the δi,AC’s are the same as δAC, where δAC is a fixed treatment effect between the treatment A and the control group C for all studies in G1 and G3.The fixed treatment effect δBC can be considered in the same way. It is important to note that the treatment effect δi,AB or its fixed effect δAB is not a free parameter since δAB = δAC − δBC.
To address the problem of between-study heterogeneity, we usually use a random effect model, i.e. assume δi,AC, δi,BC and δi,AB are random variables. If we use a normal distribution, the random effect model is to assume that the treatment effects δi,AC, δi,BC and δi,AB are normally distributed as
The parameters μAC and μBC are the overall mean effects between the control group C and the treatment A, and the control group C and the treatment B, respectively. The
where
The αi in each group is the trial effect. We can consider the following two assumptions. The first one is that the trial effects are assumed to be study-level effects, which means the αi’s are different fixed parameters. We need to include 31 different unknown parameters in the model. The second one is that we may assume a model for αi’s. A special case is to assume that all trial effects are the same: α = α1 = α2 = . . . = α31. Conversely if the trial effect is assumed to be a random effect, we may assume that
The above models are called empirical log-odds ratio models. The trial effect αi’s are no longer in the above models. Note that the models Yi,AC and Yi,BC for the studies in G1 are not independent. The treatment effects δi,AC and δi,BC are jointly normally distributed as shown in (1). The
The μAC and μBC are the overall mean effects for the models Yi,AC and Yi,BC. The variances of the models Yi,AC and Yi,BC are
2.2. Estimation
To make inference, the maximum likelihood method is applied to estimate the unknown parameters in the empirical log-odds ratio models given in (3)-(6). Our aim is to estimate the unknown parameters for the meta-analysis consisting of 31 studies. Let θ be the collection of all unknown parameters for the meta-analysis. Suppose that θ can take any value within admissible ranges Θ. The method of maximum likelihood is to find the value
Notice that the l(θ) is a summation of log-likelihoods from G1 to G4.The p(Yi,AC, Yi,BC|θi), p(Yi,AB|θi), p(Yi,AC|θi) and p(Yi,BC|θi) represent the joint probabilities or likelihoods of observing the data that has been collected in G1, G2, G3 and G4 respectively. Maximizing the log-likelihood function, we use the function nlme in the software R to solve the unknown parameters. As described in the previous section, there are two assumptions of heterogeneity parameters: homogeneity and heterogeneity variances. For the model with homogeneity variances (Model 1 in Table 1), we assume that τAC = τBC = τAB and the correlation coefficient between the treatment effects takes 1/2. For the model with heterogeneity variances (Model 2 in Table 1), the correlation coefficient is an unknown parameters. Thus, the θ in Model 1 is {μAC, μBC, τ2} while θ in Model 2 is
2.3. Numerical Results
The estimates of unknown parameters in Model 1 and Model 2 are shown in (Table 1). From Model 1, the overall means of treatment effects A versus B, A versus C and B versus C are 0.108146, -0.568930 and -0.677076 respectively and the variation between studies in those comparisons are assumed the same, 0.275320. The overall means estimated from Model 2 are quite similar. Those means for Model 2 are 0.064521, -0.599244 and -0.663766, and the variation between studies are 0.09338, 0.33440 and 0.318274 respectively. The correlation coefficient in Model 2 is 0.96. Notice that the estimator of ρ is quite close to one and τAB is very small. All treatment effects are on the log-odds ratio scale. In term of interpretation, we consider the overall means on the odds ratio (OR) scale. The results obtained from both models are quite close. They indicate that both treatment A and treatment B reduce the rates of reocclusion significantly by about 40% comparing to control group. However, the difference between treatment A and treatment B is neglect although treatment B is even slightly better than treatment A (improve by about 14% using Model 1 and 6% using Model 2). In both models, we used empirical log-odds ratio models to eliminate the nuisance parameters (trial effects). The computation is very efficient and very stable, it converges very fast for almost any starting points.
3. CONCLUSION
We demonstrated a normal approximation model based on empirical logistic transform to multi-arm trials data. The approximation is usually quite good if the number of observations in each study is not too small (the number of samples in a single study should usually be larger than 20). Since the normal distribution is used, the calculation from the normal approximation is much faster than from the model with exact binomial distributions. It takes just about 2 seconds using Model 1 for the example discussed in this paper, but it takes about 30 minutes if we use the exact binomial distributions and conditional likelihood approach (it takes about 5 minutes if an unconditional likelihood approach is used, but this method needs to estimate αs’s). The final results from both models are very close.
The estimation of ρ is quite trick. In our example, the information for ρ or τAB mainly comes from G2.Due to small number of studies involved in G2, we should be careful to explain the values of the estimates, which ρ is quite close to 1 and τ is quite close to zero. In this case, a way is to assume the between-study heterogeneity
ATC(II) Collaboration [8ATC Collaboration. Collaborative overview of randomised trials of antiplatelet therapy-II: maintenance of vascular graft or arterial patency by antiplatelet therapy BMJ 1994; 308: 159-68.] concluded that antiplatelet therapy (aspirin plus dipyridamole (A) or aspirin alone (B)) produced a highly significant (2p ≤ 0.00001) reduction in vascular occlusion in a wide range of patients. The odds of vascular graft or arterial occlusion were reduced by about 40% while treatment continued. Our numerical results in the previous section are similar to the conclusion from [8ATC Collaboration. Collaborative overview of randomised trials of antiplatelet therapy-II: maintenance of vascular graft or arterial patency by antiplatelet therapy BMJ 1994; 308: 159-68.].
ACKNOWLEDGEMENT
HC is supported by a grant from Suan Dusit Rajabhat University (SDU), Thailand.